Customize SciSure to work your way
Your lab, your workflows, your way. SciSure gives you full control over how you connect your research tools, instruments, and databases. Create custom connections that fit exactly how your team works–now and in the future.
.avif)
Trusted by 550,000+ scientists, EHS, and LabOps worldwide in 55,000+ laboratories





 Customer story
Customer story"SciSure helps us save time by enabling us to share our protocols with colleagues easily. It also takes care of our sample management."

 Customer story
Customer story“Working with the SciSure team has been a collaborative and productive experience.”


Build a platform that works for you
Ready-to-use integrations
Instantly connect SciSure to 40+ prebuilt add-ons to streamline workflows without extra setup.
Related:

40+ integrations

Free and premium add-ons

Constantly growing library
.avif)
Custom integrations with our API & SDK
Build custom integrations with SciSure’s open API and SDK to connect lab instruments, automate reporting, and sync data.
Related:

Open API

Developer SDK

Full developer support
.avif)
Flexible & adaptable to your lab’s needs
Easily integrate new tools as your lab evolves without switching platforms or disrupting workflows.
Related:

Connect any research tool

Automate your workflows

Future-proof your setup
.avif)
Connect instantly with 40+ add-ons
Our Marketplace offers a range of integrations to streamline operations, data collection, and research workflows.

Astra Iris - AI Support Assistant
AI-powered support assistant built directly into SciSure Research.

DataChaperone - Analysis & AI Platform
Automated, audit-ready data analysis directly inside your ELN.
.png)
DYMO® LabelWriter™ 550 Series
Streamline your lab labeling workflow with precision and ease
.avif)
DMPTool.org
Streamline workflows and enhance collaboration by integrating and managing data management plans from DMPTool within SciSure
.avif)
Protocols.io
Bring trusted protocols directly into your ELN
.avif)
Nikon NIS-Elements
For seamless exchange of data and notes between Nikon NIS-Elements microscopy-based imaging platform and eLabNext
Empower your lab with custom integrations
SciSure’s API and SDK give labs complete flexibility to build integrations that fit their unique workflows.



.avif)
How labs are customizing SciSure to their needs
See how research teams are connecting their tools, automating workflows, and optimizing data flow with SciSure.







See SciSure in action
Every lab is different, and SciSure is built to adapt. Book a demo today to see how our Scientific Management Platform (SMP) can transform your team’s workflows, streamline compliance, and help your research move faster.
Frequently asked questions
Everything you need to know about the product and billing.
SciSure supports prebuilt add-ons from our Marketplace, direct API connections, and fully customizable integrations via our SDK.
No. Many integrations are plug-and-play. However, some integrations require a paid license.
Most add-ons are free, while some premium integrations require a subscription. Pricing details are available in the user interface Marketplace.
Yes! SciSure’s API allows you to connect lab instruments, automate data collection, and sync results with your workflows.
Visit our Developer Portal for API documentation, SDK downloads, and integration guides.
Can’t find the answer you’re looking for? Please chat to our friendly team.
Stay ahead in lab innovation
Introduction
Research labs that rely on spreadsheets, paper logs, or disconnected point solutions eventually reach a point where the system breaks down. Sample status becomes unclear, inventory records fall out of sync, and reproducing a previous experiment requires hunting through multiple sources that may not agree with each other. Understanding the importance of a laboratory information management system in this context goes beyond feature comparisons.
A Laboratory Information Management System (LIMS) addresses these problems by changing how sample data is captured, tracked, and maintained across the lab. This article focuses on the benefits of LIMS, what specifically changes in an R&D environment when that structure is in place, and why the design of the LIMS itself determines how much of that value a lab can actually realize.
What is a LIMS and what does it actually manage?
A Laboratory Information Management System (LIMS) is a software platform that manages the data generated by laboratory samples, workflows, and operations. At its core, a LIMS tracks samples across their full lifecycle — registration, storage, transfer, and disposal — through configurable metadata, check-out/check-in, sample dispatch, lineage, and Barcode Automation. At the same time, it maintains the associated status records and audit trails that give labs confidence in their data.
The benefits of a LIMS system extend beyond sample storage. A well-designed system handles inventory, equipment records, workflow configuration, and the data relationships between them. When evaluating LIMS software for an R&D environment, it is worth understanding that a LIMS designed for the R&D sector operates differently from a clinical or QA/QC-focused system. Clinical and manufacturing LIMS tend to be built around rigid, predefined testing pipelines, while an R&D-focused LIMS is designed to support flexible, iterative workflows where sample types, metadata requirements, and experimental parameters change frequently.
The core benefits of LIMS for research labs
The advantages of a laboratory information management system in an R&D context go beyond basic sample tracking, making the choice of system a consequential infrastructure decision.
Sample traceability across the lifecycle
Without a reliable system in place, sample management depends on manual records, shared spreadsheets, and institutional memory. Samples get misplaced, their status becomes ambiguous, and when a scientist needs to trace a sample back through its history, the records required are often incomplete or inconsistent. In regulated environments, those gaps create compliance risk that is difficult to explain during an inspection.
A LIMS captures each sample at the point of registration and maintains a continuous, configurable record through every stage of its lifecycle. Check-out/check-in and sample dispatch with accept/deny functionality give labs visibility into where samples are and who is accountable for them. Barcode Automation and QR code integration allow lab teams to update sample status and location in real time, reducing the data entry errors common in paper-based systems. Lineage tracking maintains the relationship between parent and child samples across derivations, aliquots, and transfers, which is particularly valuable where sample histories need to be traceable for both scientific and regulatory purposes.
The University of Pittsburgh reported a 50% improvement in sample tracking efficiency after implementing systematic sample management, a result that reflects how much time is lost when labs rely on manual processes to maintain that visibility.
Reducing manual entry with triggers and automation
Labs running on paper records or Excel spend a disproportionate amount of time on data entry, status updates, and manual notifications. These tasks add administrative load without contributing to the scientific work itself, and transcription errors introduced during manual data transfer between instruments, notebooks, and reporting systems can affect the integrity of results without being immediately obvious.
A LIMS reduces this burden by capturing data closer to the point of generation and connecting it to the relevant sample and experiment records. Instrument data can be associated directly with the samples being analyzed, cutting out the manual steps between data generation and record keeping. Triggers & Automations allow labs to configure notifications, status changes, and task creation based on defined conditions, so that routine follow-up actions happen consistently without requiring manual intervention each time. This is particularly useful for test scheduling, expiration monitoring, and cross-team handoffs where delays caused by missed notifications have real consequences for lab throughput.
The cumulative effect across multiple workflows is significant. Food Brewer AG reported a 60% increase in R&D productivity after moving away from manual processes, reflecting the time and focus that teams recover when routine administrative tasks are handled systematically.
Audit readiness and compliance documentation
Inspection preparation is one of the most resource-intensive activities in a regulated research lab, and the difficulty is rarely a lack of underlying data. It is a lack of organization around it. When records are maintained across paper binders, email threads, and point solutions, assembling the documentation required for an audit means locating, cross-referencing, and reformatting records that were never designed to be retrieved together. That process is slow and typically falls on a small number of people who know where everything is kept.
A LIMS generates audit logs automatically as users interact with samples, workflows, and inventory, creating a timestamped record of activity without requiring a separate documentation effort. For R&D labs operating under FDA 21 CFR Part 11, GxP requirements, or ISO 27001, the evidence required to demonstrate compliance is maintained as part of daily operations rather than assembled ahead of each inspection. Compliance is embedded into how the lab works day to day, not treated as a periodic reporting exercise.
The operational impact is direct. Arctic Therapeutics achieved ISO 15189 accreditation and reported saving two hours per week on compliance documentation after moving to this approach, time that had previously been spent on manual preparation tasks the system now handles automatically.
Reproducibility and structured research records
Reproducibility problems in research are often framed as a question of scientific rigor, but the root cause is frequently administrative. When experiment records are kept in paper notebooks, Word documents, or spreadsheets, the information captured varies by individual. Protocol versions go unrecorded. Sample references are inconsistent. When a scientist leaves a project, the knowledge embedded in those records often becomes inaccessible.
A LIMS captures sample-related work in a consistent, searchable, version-controlled format. Configurable metadata schemas and standardized data entry mean records are comparable across experiments, teams, and time periods. Version control ensures changes are tracked and attributable, and search functionality allows relevant historical data to be retrieved without relying on whoever originally created the record. For R&D organizations where the long-term value of research data depends on its usability across teams and time, this consistency is one of the most consequential advantages a LIMS delivers.
Inventory and resource visibility
Sample management and inventory management are closely connected, but many labs track them separately or not systematically at all. Reagents run out without warning. Consumables expire before they are used. The result is unplanned disruption to experiments, unnecessary reordering, and spending that is difficult to account for.
A LIMS extends systematic tracking to reagents, consumables, and equipment alongside sample records. Stock levels are visible in real time, and threshold-based alerts through Triggers & Automations notify the relevant people when items need reordering. The Supplies & Ordering module supports procurement workflows directly within the system, and expiration tracking reduces waste by making it clear which materials are approaching the end of their usable life.
Scalability across sites and teams
The processes that work for a single lab team frequently break down as an organization grows. Shared spreadsheets become difficult to maintain consistently across groups. Local conventions for sample naming, metadata entry, and record keeping diverge between sites. When leadership needs visibility into research activity or inventory status across multiple locations, consolidating that information requires manual effort that scales poorly.
A LIMS provides a configurable infrastructure that accommodates multiple sites, teams, and user roles within a single system. Role-based access controls allow organizations to define precisely what each user or group can view, edit, and approve, maintaining data integrity as the number of users increases. Multi-site configuration means each location can operate according to its own workflows while contributing to a shared data environment that supports centralized oversight. For research organizations managing labs across different regulatory jurisdictions or planning to expand, this flexibility reduces the operational risk that typically accompanies growth.
Why a LIMS designed for R&D is different
The category of LIMS covers a wide range of products, and the differences between them are not always apparent from feature lists alone.
Clinical and manufacturing LIMS are typically designed for high-volume, predefined testing pipelines. The assumption embedded in those systems is that sample types, test panels, and reporting formats are largely fixed. That design works well for its intended context but does not translate well to R&D environments, where experimental parameters change frequently and workflows evolve alongside research questions.
A LIMS designed for the R&D sector operates on a different set of assumptions. Sample types and metadata schemas are configurable. Workflows can be adapted as research evolves. The system sits alongside protocols, experiments, equipment records, inventory, and compliance documentation, and the advantages of a LIMS in an R&D context depend in part on how well it connects to those adjacent areas. The laboratory information system benefits that matter most to R&D teams depend on a system that was designed for those requirements from the outset.
How LIMS and ELN work together
When a LIMS and an ELN operate as separate tools, experiments are documented in one system, sample data is managed in another, and there is no native link between the two. A scientist documenting an experiment needs to manually reference the samples involved, cross-checking records across systems that were never designed to communicate with each other.
A LIMS that connects workflows with an electronic lab notebook addresses this directly. Experiments can reference samples in context, so scientists have visibility into sample status, metadata, and lineage without switching between disconnected records. Samples link to the results generated from them, and those results sit within the experiment records where they belong. For R&D labs where reproducibility and traceability depend on following a clear line from experimental design through to results, the connection between LIMS and ELN is what makes the records produced by each system fully usable.
Signs your lab needs a LIMS (or a better one)
Not every lab problem points to a LIMS gap, but several specific patterns tend to indicate that the current system is creating more friction than it resolves. Understanding the advantages of a LIMS system starts with recognizing where existing processes are falling short.

Samples are getting lost or their status is unclear. If lab teams regularly spend time locating samples, reconciling conflicting location records, or discovering that a sample was consumed or disposed of without that being recorded, the tracking system is not doing its job. Sample loss and status ambiguity are among the most direct indicators that traceability has broken down.
Reproducing previous experiments requires significant investigation. When re-running an experiment means tracking down the scientist who originally ran it, or piecing together records from multiple sources that do not fully agree, the documentation system is not capturing enough context. Reproducibility problems that stem from record-keeping gaps are a reliable signal that the current approach is insufficient.
Audit preparation takes weeks. If the process of preparing for an inspection requires manually locating, formatting, and cross-referencing records that should already be accessible in a consistent format, the compliance documentation process is reactive rather than embedded in daily operations.
A significant portion of lab time goes to data entry and status updates. Manual transcription between instruments, notebooks, and reporting systems is not just inefficient. It introduces errors that are difficult to detect and correct after the fact. If lab teams are spending meaningful time on this kind of administrative work, that is time not spent on analysis.
Different teams or sites are working from inconsistent records. When sample naming conventions, metadata fields, and workflow steps vary between groups, cross-team collaboration becomes unreliable. Inconsistency at this level also makes it difficult for leadership to get an accurate picture of lab activity across the organization.
Inventory records do not reflect reality. If reagents run out unexpectedly, consumables expire unused, or procurement decisions are made based on estimates rather than current stock data, inventory visibility is insufficient. This is a common problem in labs where sample and inventory tracking are handled separately.
Any one of these patterns can be managed individually for a period of time. When several appear together, they typically indicate a systemic gap in how laboratory data is being captured and maintained.
What to look for when evaluating LIMS software
Selecting a LIMS is a long-term infrastructure decision, and the criteria that matter most depend on the specific context of the lab. That said, several evaluation points apply broadly to R&D environments regardless of size or discipline.
R&D-specific configuration. Verify that the system can be configured to match how the lab actually works, and ask vendors specifically how it handles changes to sample types or workflow steps after initial setup.
ELN integration capability. A LIMS with no integration path to an electronic lab notebook will leave that gap in place. Look for native integration or well-documented API connectivity between the two systems.
Sample traceability depth. The system should be able to answer questions about where a sample came from, what happened to it, and what experiments it was associated with.
Compliance certifications. Verify certifications directly rather than taking general compliance claims at face value. Some platforms, including SciSure , carry ISO 27001 and HIPAA certifications in addition to FDA 21 CFR Part 11, GxP, and SOC 2 Type II.
API and integration ecosystem. Evaluate the depth of the API, the availability of SDKs, and whether the vendor maintains an active integration ecosystem or marketplace.
Role-based access controls. Evaluate how granular the access control system is and whether it can accommodate the organizational structure of the lab.
Scalability for multi-site environments. Evaluate how the system handles cross-site visibility, centralized administration, and consistency of records across locations.
Taken together, these criteria help distinguish a system that will deliver the full benefits of using a LIMS over time from one that solves immediate pain points but creates new constraints as the lab grows.
The real value of LIMS starts with structured data
The difference between a lab running on fragmented records and one running on well-maintained, connected data compounds over time. Decisions improve when the underlying information is reliable. Audits become less disruptive when records reflect what actually happened. Research moves faster when previous work is accessible and verifiable.
If your lab is evaluating whether a more structured approach to research data management would address the gaps you are working around, SciSure is worth a closer look.
FAQ
What is a LIMS system used for?
A Laboratory Information Management System (LIMS) manages the data associated with laboratory samples, workflows, inventory, and equipment. In an R&D context, this includes registering and tracking samples across their lifecycle, maintaining configurable metadata, managing reagents and consumables, and keeping the records that regulated research environments require.
What are the advantages of a LIMS for research labs?
The main benefits for research labs include improved sample traceability, more reliable reproducibility, reduced manual data entry, stronger audit readiness, and better visibility into inventory and resource usage. These benefits are most pronounced when the system fits the lab's actual workflows. Platforms like SciSure are designed specifically for R&D environments, which affects how these benefits are realized in practice.
What is the difference between a LIMS and an ELN?
A LIMS manages sample data, inventory, and operational records. An electronic lab notebook documents experiments, protocols, and results. When the two operate independently, there is no native link between experiment records and the sample data they reference. SciSure LIMS Research connects workflows between both, so experiments reference samples directly and records are visible in context.
How does a LIMS improve compliance and audit readiness?
A LIMS maintains timestamped, attributable records of laboratory activity as part of normal operations. Audit logs are generated automatically, access controls define who can modify records, and data integrity requirements are enforced at the system level. SciSure LIMS supports FDA 21 CFR Part 11, GxP, and SOC 2 Type II, alongside ISO 27001 and HIPAA, depending on the lab's regulatory context.
What should I look for when choosing a LIMS?
The criteria covered in the “What to look for when evaluating LIMS software” section above apply here. If you want a quick shortlist of red flags to watch for: rigid workflows that cannot be reconfigured post-deployment, no native or documented ELN integration, vague compliance claims without certifiable evidence, and limited API access that locks you into the vendor’s ecosystem. SciSure LIMS is worth evaluating against those criteria if you are looking for a system designed specifically for research environments.
Can a LIMS integrate with lab instruments and other software?
Integration capability varies significantly between platforms. Look for open APIs, available SDKs, and an active ecosystem of supported connections. SciSure LIMS provides open APIs, SDKs, and a Marketplace of add-ons that allow labs to connect instruments, extend platform functionality, and push data between systems via API, SDK, webhooks, and Marketplace add-ons.

Benefits of LIMS for R&D Labs | SciSure
Explore the key benefits of LIMS for research labs, from sample traceability and workflow automation to audit readiness and reproducible science.
If you’ve spent any meaningful time in a research lab, you know that specimen management sounds straightforward until it isn’t. Collect samples, label them, store them, track what happens to them. In theory, simple. In practice, it’s one of the most persistent sources of wasted time, lost data, and quiet frustration in labs of every size. The freezer inventory that exists only in someone’s head. The Excel sheet that three people edit independently. The unlabeled tube that could be anything from a bacterial lysate to a patient-derived serum sample. These aren’t edge cases. They’re Tuesday.
What does lab specimen management actually involve?
Specimen management covers the full lifecycle of any physical sample your lab works with: biological materials like bacterial cultures, cell lines, tissue sections, blood, serum, DNA and RNA extracts; chemical and biochemical specimens such as reagent libraries, metabolite panels, and antibody stocks; clinical specimens including biopsies, saliva, urine, and plasma; environmental samples; and genomic or proteomic materials such as sequencing libraries, CRISPR reagents, and protein preparations.
Each of these has its own handling requirements, stability windows, regulatory considerations, and downstream dependencies. A microbial culture collection has different storage and passage-tracking needs than a biobank of clinical serum samples. A reagent library supporting a drug screening campaign needs different metadata than soil samples in an ecology study.
The common thread is that every specimen needs to be unambiguously identified, traceable through every interaction, stored under the right conditions, and documented well enough that someone else - or you, six months from now - can pick up exactly where things left off.
Where lab specimen management breaks down
Rather than listing generic problems like “manual errors” and “inefficiencies,” it’s more useful to describe the specific failure modes that are hard to catch in the moment and expensive to fix after the fact.
Inconsistent labeling
When two lab members change a labeling convention and no one’s around to document the transition, the metadata suffers even if the samples are fine. Or, for example, if there are no enforced standards, no guaranteed links to experimental contexts, or no redundancy if the label degrades. With most labs identifying specimens based on handwritten labels or locally printed stickers, the information on it is simply whatever the person collecting the sample decided was important at that moment. A freezer box of DNA extracts can become effectively useless because of these “slip ups.”
Tracking fragments across disconnected systems
When someone asks, “How many aliquots of strain X do we have, and which experiments have used them?”, answering probably requires cross-referencing three systems, interpreting two people’s handwriting, and probably opening a freezer to physically count. This is what you get when specimens live in a freezer log, or experimental use gets recorded in a notebook or ELN, or inventory levels get tracked somewhere else entirely. (Or not at all.)
In a lab of 15 people, this is annoying. In a lab of 80, it’s a structural problem that costs hours every week.
Chain of custody gaps that surface at the worst possible time
If your lab operates under any regulatory framework - GLP, GCP, ISO 17025, or institutional biosafety protocols - you need to demonstrate who handled a specimen, when, and what they did with it. In manual systems, this documentation is reconstructed after the fact, if it’s created at all. The gap is invisible until an auditor asks for it, or until a result is challenged, and you can’t demonstrate the integrity of the sample it was based on.
For biotech and pharma labs moving toward IND-enabling studies, this isn’t a nice-to-have. It’s a gating requirement.
Specimens degrade silently
A freezer that drifts two degrees overnight. A reagent past its validated stability window. A cell line aliquot that’s been through one too many freeze-thaw cycles because people keep pulling from the same stock instead of working from designated working aliquots. None of these announce themselves. You discover them when an assay fails, when results don’t replicate, or when a QC check catches something downstream. By then, you’ve lost not just the specimen but potentially weeks of work that depended on it.
Scaling makes every weakness structural
A five-person academic group can often manage specimens through informal systems and institutional knowledge; but when that group grows to 20, or when a biotech scales from 30 to 100 people, every informal practice becomes a liability. New team members don’t know the unwritten conventions. Storage space gets allocated ad hoc. Nobody owns the inventory as a whole. The transition from “we manage” to “we’ve lost control” happens gradually and usually isn’t recognized until something forces the issue.
What a centralized specimen management system looks like
The failure modes above share a root cause: fragmentation. Fragmented identification, fragmented tracking, and fragmented documentation. Addressing them means going beyond adding more tools. Rather, when you replace the patchwork with a single system where specimen data, experimental records, and inventory all live together:
Specimens become findable in seconds, not minutes
When your storage infrastructure is modeled digitally - down to the freezer, shelf, rack, box, and position - retrieving a specimen means searching, locating, and closing the freezer. Not holding the door open while scanning labels, which incidentally is one of the most common causes of the temperature excursions mentioned earlier. These time savings compound across every person in the lab, every day. This search also tells you about the sample's current state, including whether it's in use, reserved, depleted, or awaiting QC (quality control), so you don't make the trip to the freezer just to find out someone took the last vial yesterday.
Traceability becomes automatic, not administrative
When every interaction with a specimen - creation, transfer, aliquoting, use, disposal - is logged as a natural consequence of working in the system, chain of custody stops being something your team must remember to document. For academic labs, this supports reproducibility and publication integrity. For regulated environments, it generates the audit trail that GLP, GCP, and ISO frameworks require without adding bureaucratic overhead.
Sample lineage stays intact across months and team members
Structured and queryable relationships between samples mean you can trace any result back to its source. This is particularly relevant in molecular biology and microbiology workflows, where a single source specimen can generate dozens of derivatives over months of work. For example, parent-child relationships between the original clinical sample and its aliquots, the master cell bank and its passages, the genomic extraction, and the sequencing library. When you can't explain how these are related, you have an accumulation of tubes instead of a managed collection.
Problems get caught before they cascade
Continuous environmental monitoring with automated alerts means a freezer excursion triggers a notification - not a failed assay three weeks later. Expiry tracking means your team acts on specimens approaching their stability window rather than discovering degradation downstream. The shift from reactive to proactive is where most of the hidden cost savings live.
Growth doesn’t break your processes
A system that handles 500 specimens with the same rigor as 50,000 means you don’t rebuild your infrastructure every time the lab scales. Batch operations handle high-throughput intake without sacrificing individual-level traceability. Role-based access ensures that as your team grows, accountability and data security grow with it. This matters particularly during the transitions that growing biotechs know well - the Series A hire surge, the CRO partnership, the multi-site expansion.
Collaboration happens without losing control
Sharing specimen data with a CRO, an academic collaborator, or a second site shouldn’t require exporting spreadsheets and hoping version control holds. Secure transfer of relevant data - without exposing your entire inventory - is what makes multi-party research manageable.
At SciSure, these capabilities come together in a single platform that integrates ELN and LIMS - meaning specimen data isn’t separated from the experimental records that give it context. It also means security stops being patchworked. Encryption, access controls, hosting compliance, and audit logging are properties of the system, not properties assembled across five different vendors with five different review processes.
This architectural choice reflects a conviction that specimen management doesn’t exist in isolation: it’s part of how research gets done, and the tools should reflect that.
How Arctic Therapeutics consolidated their lab workflows
After adopting SciSure, Arctic Therapeutics - a growth-stage Icelandic biotech running drug development programs across Alzheimer's, Parkinson's, and rare-disease research - now works with consolidated samples, inventory, equipment, and experiments into a single system. The team reports having saved approximately 2 hours per week on registration and inventory tasks alone, with full sample-and-reagent traceability and audit-ready documentation through controlled access, electronic signing, and record locking.
Before centralizing, the laboratory team of around 10 specialists managed experiment documentation, inventory, and equipment logs across spreadsheets, paper records, and a mix of digital platforms. Samples and reagents weren't QR coded, so traceability was limited - a real problem for a lab operating under ISO 15189 (the international standard for quality and competence in medical laboratories) and supporting clinical workflows.
As Laboratory Director Olga Ýr Björgvinsdóttir summarizes, the team can now "save at least 2 hours per week, while also strengthening our ISO 15189 compliance."
How to improve specimen management in your lab
- Start with centralization, not optimization.
The most damaging decision a growing lab makes is layering another tool on top of existing fragmented processes. If your specimens, inventory, and experimental records live in three different places, bringing them together will deliver more value than improving any one of them individually.
- Define your metadata schema before you start entering data.
Decide what fields every specimen type needs and enforce them. The time spent upfront saves an order of magnitude more in retrieval, reporting, and troubleshooting later.
- Automate identification.
Barcode labeling eliminates the single largest source of specimen management errors. The cost is trivial compared to a single misidentified sample in a regulatory submission or a published study.
- Invest in training as an ongoing practice.
A system is only as good as the consistency with which people use it. This is especially important in academic labs with regular student and postdoc turnover, and in growing companies onboarding new scientists rapidly.
- Monitor storage conditions continuously, not reactively.
If you’re only checking freezer temperatures when something seems wrong, you’re accepting risks you don’t need to.
The work isn't glamorous, but it matters.
Nobody gets into science because they’re passionate about freezer inventory, but it is foundational. The integrity of your data depends on the integrity of your samples. The efficiency of your lab depends on how quickly people can find, verify, and use what they need. And your ability to meet regulatory requirements, reproduce results, and collaborate across teams depends on having a system that doesn’t rely on individual memory or informal conventions.
Whether you’re a small academic group trying to stay organized or a growing biotech preparing for your first regulatory submission, the principles are the same. The only question is whether you systematize them now or pay the cost of not doing so later.
If this resonates, we’d welcome a conversation - not a sales pitch, but a practical discussion about what’s working in your lab and what isn’t.

Specimen Management in the Lab: What’s Actually Going Wrong & How to Fix It
Discover how digital solutions like SciSure can improve lab specimen tracking, storage & data integrity while keeping things efficient.
When experiment timelines stretch in most research organizations, slow progress has less to do with assay difficulty or experimental design; it has more to do with coordination gaps between people, systems, and steps in the workflow. Samples wait for assignment. Approvals sit in inboxes. Data review gets delayed because no one has visibility into queue length. Rework resets the clock because required metadata wasn’t captured upfront.
Individually, these delays seem minor. Collectively, they compound, quietly extending experiment and research turnaround time across teams and projects.
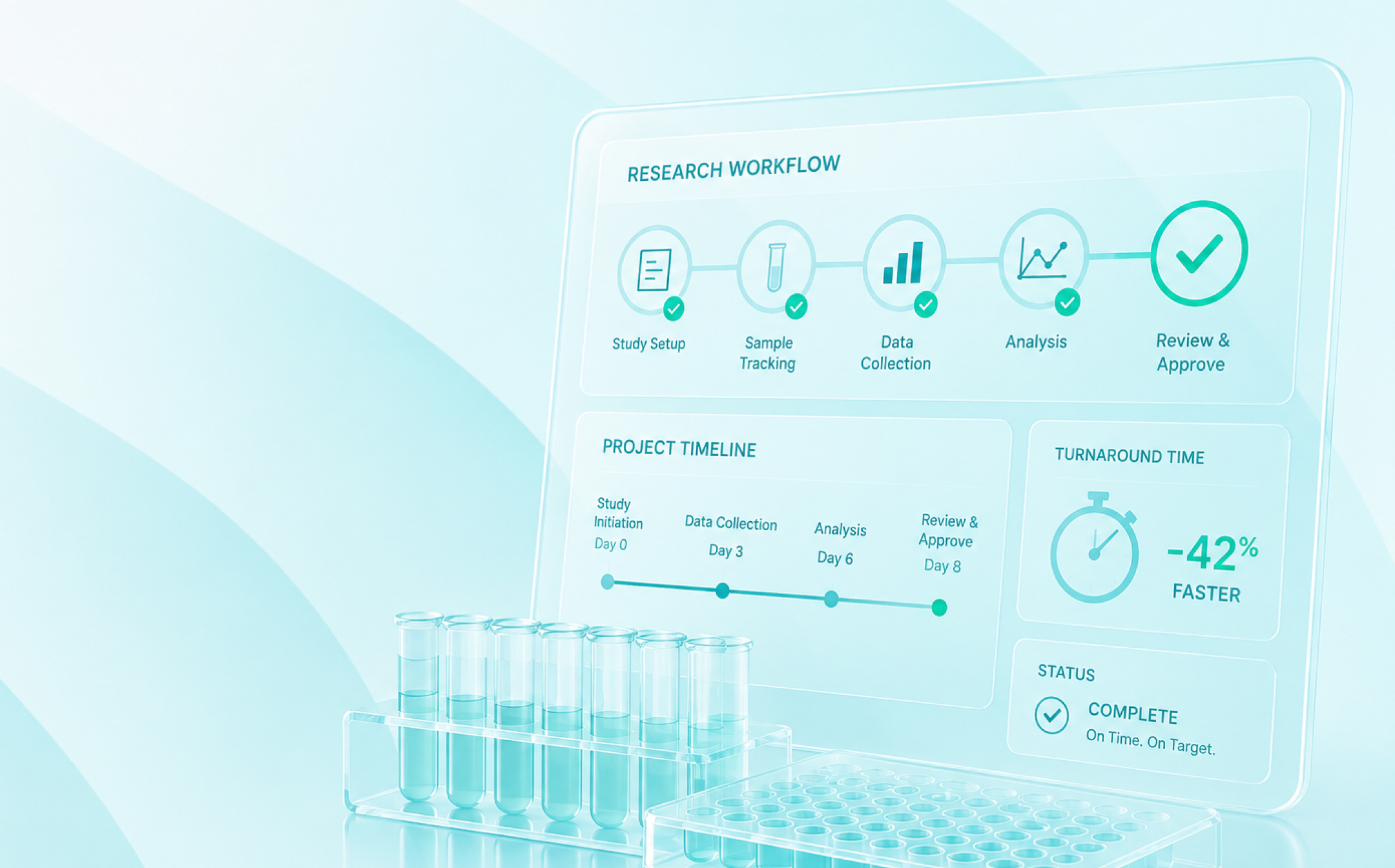
The real challenge lies in how work moves between those stages. If you want to improve lab turnaround time, you have to look beyond individual experiments and examine how work flows through the system.
This is where digital research management tools make a measurable difference. When workflows are structured, handoffs are automated, and teams have real-time visibility into task status and sample movement, delays become predictable, and preventable.
In this guide, we’ll walk through a practical, step-by-step approach to improving lab turnaround time by:
- Identifying where time is actually being lost
- Eliminating ambiguous task handoffs
- Automating passive waiting steps
- Making sample flow visible and predictable
- Reducing rework through structured data capture
- Monitoring turnaround time as an operational KPI
Step 1: Map where time is actually being lost
If you want to improve lab turnaround time, start by measuring the full research lifecycle. Not just the bench work. Most labs can tell you how long an assay takes to run. Far fewer can tell you how long samples wait before assignment, how long approvals sit in review, or how often experiments reset due to missing information. Turnaround time is elapsed time, from request or design to validated result. And much of that time isn’t active experimentation. It’s waiting.
Common hidden delays include:
- Samples sitting in intake queues
- Experiments paused pending safety or material approvals
- Data waiting for review or signoff
- Rework caused by incomplete metadata or documentation
In fragmented environments, these stages are spread across disconnected systems: ELNs, inventory tools, spreadsheets, inboxes. That fragmentation makes delays hard to trace and even harder to fix.
The first practical step is creating end-to-end visibility across the research lifecycle. A connected research management platform like SciSure timestamps workflow transitions, tracks sample status in real time, and surfaces stalled tasks before deadlines slip. When you can see queue lengths, average cycle times, and where work consistently pauses, patterns emerge. And once patterns are visible, lab turnaround time stops being a mystery metric. It becomes something you can actively manage.
Here are 5 organizational risks that fragmented lab systems create and why an integrated system is mission-critical.
Step 2: Eliminate ambiguous handoffs
To improve lab turnaround time, make sure you're targeting handoff failures. When coordination depends on email threads, verbal updates, or informal tracking, ownership becomes unclear. Tasks sit idle not because no one is capable of doing them, but because no one is explicitly accountable. For example, when a finished experiment remains waiting for review, samples are logged but not assigned, or data is ready but no one knows it requires approval.
Digital research management workflows replace informal coordination with structured task assignment. SciSure defines these transition points explicitly. For example:
- When an experiment is marked “complete,” the system automatically assigns the data review task to a named QA role.
- When a sample is received, it is routed to the appropriate queue based on study type or priority.
- If a review step exceeds a defined time threshold, an alert or escalation is triggered.
Instead of asking, “Who’s handling this?” the system already knows. Role-based task routing, automated notifications, and escalation rules ensure that work transitions cleanly from one stage to the next. No inbox archaeology. No status-chasing meetings.
Step 3: Automate the “waiting work”
Automated digital research management workflows can prevent delays from unclear ownership and passive waiting. For example, steps that require validation, confirmation, or approval before work can continue, e.g., safety reviews, material release checks, QA signoff, and data validation. Unlike ambiguous handoffs, these delays occur even when ownership is clear, because progression depends on formal control steps.
Each of these steps is necessary. But when they’re managed manually, they introduce unpredictable delays. An approval request gets buried in email. A reviewer doesn’t realize a task is pending. An experiment isn’t documented correctly, so the workflow resets. Individually, these pauses seem small. Collectively, they stretch lab turnaround time significantly.
Within SciSure, conditional workflows ensure that:
- Approval steps are built into the workflow and automatically triggered when an experiment reaches a defined status (e.g., “Ready for QA Review”).
- Required data fields and documentation must be completed before the system allows progression to the next stage.
- Sample status cannot advance until prerequisite actions (such as safety confirmation or material verification) are logged.
- Dashboards surface pending approvals and aging tasks, making delays visible before they become bottlenecks.
Instead of relying on someone to remember the next step, the system advances it automatically. This reduces invisible wait time: the hours or days where no one is actively working, but the experiment is still not progressing.
Step 4: Make sample flow predictable
Improving turnaround time requires making sample lifecycle status visible in real time. Predictable sample flow reduces idle time between processing stages, prevents unnecessary rework, and shortens overall experiment turnaround time. Not by accelerating individual steps, but by reducing friction between them.
Even well-designed experiment workflows can stall if sample tracking is poor. In many labs, samples pass through multiple stages: intake, preparation, analysis, storage, disposal – but visibility into their status is fragmented. Teams rely on spreadsheets, manual logs, or hallway conversations to understand where material is and what happens next.
Common issues include:
- Samples sitting unassigned after receipt
- Priority samples mixed into general queues
- Capacity bottlenecks at shared instruments
- Delays caused by incomplete chain-of-custody records
Within the SciSure platform, samples can be tracked from receipt through processing and final disposition within a centralized system. Status changes are logged automatically as samples move between workflow stages. Teams can view queue depth, identify backlogs, and prioritize work based on predefined criteria such as study type or urgency.
When sample location, ownership, and status are transparent, fewer delays occur due to uncertainty. When scientists don’t have to ask, “Where is this sample?” or “Is this ready for analysis?” work progresses more consistently.
Here's an example from the field: Euroimmun US - a diagnostics company within Revvity. Before SciSure, the team managed samples through Excel spreadsheets and undocumented institutional knowledge held in staff memory. As the company scaled, sample status became scattered across multiple document versions. This forced the team to repeatedly revisit and reconcile data points before work could move forward.
After implementing SciSure, sample organization, retrieval, and status tracking moved into a single live system, cutting the time and resources spent on sample-related activities. The team can now locate samples faster, reduce mix-ups and unnecessary freeze-thaw cycles, and filter inventory across cohorts and test types - turning sample management from a coordination bottleneck into a predictable, searchable workflow.
"...With the SciSure platform, our organization has dramatically reduced the time and resources required for all sample-related activities. The proper, live, and adjustable organization system streamlines sample access in a way that impacts all scientific teams within our organization."
— Kiprian Gernat, Internal Application Scientist, Revvity's Euroimmun US
Read more: How Euroimmun US Streamlined Sample Management and Saved Time with SciSure
Step 5: Reduce rework through structured data capture
When data is captured in a structured and consistent way, downstream review becomes faster and more predictable. Reviewers spend less time chasing missing information and more time evaluating results. Fewer documentation gaps mean fewer resets. Fewer resets mean shorter cycle times. Shorter cycle times improve overall lab turnaround time. When structure is built into the system, speed and rigor stop competing – they reinforce each other.
For example, an experiment runs successfully, but documentation is incomplete, metadata is inconsistent, version control is unclear, or a required safety field was skipped. In many cases, oversights like these result in the research pausing while corrections are requested, or rework is completed - and the clock resets. These resets rarely show up in formal reporting. But across multiple experiments they compound into significant delays.
Within SciSure, experiment templates, required fields, and standardized data structures can be configured to guide users through documentation as work is performed – not after the fact. Metadata requirements are embedded directly into experiment records. Inventory usage can be logged in context. Status changes are recorded automatically.
Because improving lab turnaround time isn’t just about moving work forward faster. It’s about preventing it from moving backward.
Step 6: Monitor lab turnaround time as an operational KPI
If cycle time matters (and it always does in research environments), it should be monitored continuously. When lab turnaround time is treated as a visible operational KPI, improvement becomes systematic rather than reactive. Teams can set targets, monitor trends over time, and adjust workflows before delays cascade across projects.
In many organizations, turnaround time is only examined when a deadline slips or a project falls behind. By then, the delays are already baked in. Teams reconstruct what happened, identify bottlenecks retrospectively, and move on, without changing the underlying system.
Improving lab turnaround time isn’t a one-time workflow redesign. It’s an ongoing operational discipline. Within the SciSure platform, workflow transitions, experiment status updates, and sample movements are timestamped automatically as part of daily activity. That operational data can be surfaced through dashboards and reporting views to provide visibility into:
- Average time to completion by experiment type or study
- Time spent in specific workflow stages (e.g., review, intake, analysis)
- Aging tasks and pending approvals
- Queue depth by function or team
- Frequency of rework or status reversals
This level of visibility changes the conversation. Instead of asking, “Why was this late?” leaders can ask, “Where are we consistently losing time?” A recurring delay in QA review may signal capacity imbalance. A growing intake queue may point to resourcing gaps. A spike in rework could indicate unclear documentation standards.
Faster results start with better systems
An improved lab turnaround time is the outcome of your operational design. When workflows are structured, handoffs are clear, control points are embedded, and sample movement is visible, progress becomes consistent. Delays are identified earlier. Rework decreases. Idle time between stages shrinks.
Digital research management tools like SciSure provide the operational infrastructure that allows teams to coordinate work deliberately rather than reactively. And when coordination improves, timelines stabilize.
Science will always carry uncertainty. But the way work flows through your lab doesn’t have to. Improve the system, and lab turnaround time improves with it. Because faster science isn’t about pushing people harder. It’s about designing systems that remove unnecessary friction.
If you’re ready to rethink how work moves through your lab, connect with our team to explore what’s possible.
How to Improve Lab Turnaround Time with Digital Research Management Tools
Learn how to improve lab turnaround time with structured workflows, automated approvals, and real-time tracking across the research lifecycle.