Customize SciSure to work your way
Your lab, your workflows, your way. SciSure gives you full control over how you connect your research tools, instruments, and databases. Create custom connections that fit exactly how your team works–now and in the future.
.avif)
Trusted by 550,000+ scientists, EHS, and LabOps worldwide in 55,000+ laboratories









 Customer story
Customer story“Working with the SciSure team has been a collaborative and productive experience.”
 Customer story
Customer story"SciSure helps us save time by enabling us to share our protocols with colleagues easily. It also takes care of our sample management."
 Customer story
Customer story“I'm thoroughly impressed with how SciSure has transformed our daily operations.”
“SciSure cuts down time and energy spent on tasks. I’ve loved working with it.”
 Customer story
Customer story“We’ve replaced Excel, paper, and Access databases with efficiency, turning manual tasks from hours into minutes.”
Customer story“Working with the SciSure team has been a collaborative and productive experience.”
Customer story"SciSure helps us save time by enabling us to share our protocols with colleagues easily. It also takes care of our sample management."
Customer story“I'm thoroughly impressed with how SciSure has transformed our daily operations.”
“SciSure cuts down time and energy spent on tasks. I’ve loved working with it.”
Customer story“We’ve replaced Excel, paper, and Access databases with efficiency, turning manual tasks from hours into minutes.”
Build a platform that works for you
Ready-to-use integrations
Instantly connect SciSure to 40+ prebuilt add-ons to streamline workflows without extra setup.
Related:

40+ integrations

Free and premium add-ons

Constantly growing library
.avif)
Custom integrations with our API & SDK
Build custom integrations with SciSure’s open API and SDK to connect lab instruments, automate reporting, and sync data.
Related:

Open API

Developer SDK

Full developer support
.avif)
Flexible & adaptable to your lab’s needs
Easily integrate new tools as your lab evolves without switching platforms or disrupting workflows.
Related:

Connect any research tool

Automate your workflows

Future-proof your setup
.avif)
Connect instantly with 40+ add-ons
Our Marketplace offers a range of integrations to streamline operations, data collection, and research workflows.

Astra Iris - AI Support Assistant
AI-powered support assistant built directly into SciSure Research.

DataChaperone - Analysis & AI Platform
Automated, audit-ready data analysis directly inside your ELN.
.png)
DYMO® LabelWriter™ 550 Series
Streamline your lab labeling workflow with precision and ease
.avif)
DMPTool.org
Streamline workflows and enhance collaboration by integrating and managing data management plans from DMPTool within SciSure
.avif)
Protocols.io
Bring trusted protocols directly into your ELN
.avif)
Nikon NIS-Elements
For seamless exchange of data and notes between Nikon NIS-Elements microscopy-based imaging platform and eLabNext
Empower your lab with custom integrations
SciSure’s API and SDK give labs complete flexibility to build integrations that fit their unique workflows.



.avif)
How labs are customizing SciSure to their needs
See how research teams are connecting their tools, automating workflows, and optimizing data flow with SciSure.







See SciSure in action
Every lab is different, and SciSure is built to adapt. Book a demo today to see how our Scientific Management Platform (SMP) can transform your team’s workflows, streamline compliance, and help your research move faster.
Frequently asked questions
Everything you need to know about the product and billing.
SciSure supports prebuilt add-ons from our Marketplace, direct API connections, and fully customizable integrations via our SDK.
No. Many integrations are plug-and-play. However, some integrations require a paid license.
Most add-ons are free, while some premium integrations require a subscription. Pricing details are available in the user interface Marketplace.
Yes! SciSure’s API allows you to connect lab instruments, automate data collection, and sync results with your workflows.
Visit our Developer Portal for API documentation, SDK downloads, and integration guides.
Can’t find the answer you’re looking for? Please chat to our friendly team.
Stay ahead in lab innovation
Starting a new lab gives you a rare advantage: you can design your research recordkeeping before habits, folders, freezer maps, and paper notebooks become hard to change.
Does that mean necessarily switching to an electronic lab notebook (ELN) from day one? Not necessarily. Setting up a new lab is difficult enough and you do need a practical implementation strategy. With an ELN in the mix, you also need clear project structure, searchable metadata, sample traceability, protocol control, permissions, review workflows, training, and a plan for how paperless work will become the daily default.
At the same time, a good ELN implementation helps your team answer these simple but critical questions:
- Where should this experiment live?
- Which protocol version was used?
- Which sample, reagent lot, instrument, or file supports the result?
- Who entered or changed the record?
- Can another scientist find, understand, repeat, and review the work later?
If that's the kind of lab you'd like to build, keep reading.
Why should a new lab implement an ELN before experiments start?
A new lab should implement an ELN before experiments start because the first records you create become the foundation for how your team searches, repeats, reviews, and trusts research later.
In a new lab, every early decision becomes a precedent. If your first postdoc creates one folder structure, your lab manager creates a separate freezer spreadsheet, or the new grad student stores protocol changes in shared-drive PDFs, you (the beleagured PI) have already started building the disconnected system you were trying to avoid.
An ELN gives you a cleaner starting point. You can define how research should be captured before the lab becomes busy:
- A protein engineering team can decide how constructs, plasmids, sequencing files, expression conditions, and assay results will connect.
- A cell culture lab can standardize passage records, freezer locations, media lot numbers, contamination checks, and protocol versions.
- A materials science lab can connect synthesis conditions, reagent batches, instrument files, curing parameters, and characterization images.
- A translational research group can define which studies need review, signatures, sample lineage, and controlled access.
The goal is to make the right workflow the easiest workflow. Your scientists should not have to decide from scratch where to store each result, which sample ID to use, or which protocol version is current.
How do you implement a paperless lab environment while protecting data integrity, accessibility, and user adoption?
To implement a paperless lab environment, define the record model, configure integrity controls, make records searchable, train users through real workflows, and retire paper only after each priority workflow is working reliably in the ELN.
Use this practical sequence:
A paperless lab is successful when the ELN becomes the source of research context. That means scientists can create an experiment, link samples, attach images or instrument output, use the approved protocol, request review, and retrieve the record later without maintaining a parallel notebook or spreadsheet.
What should you decide before choosing an ELN for a new lab?
Before choosing an ELN, decide what your lab must document, what data needs to stay traceable, who needs access, and which workflows need structure from day one. Avoid evaluating ELNs only through a generic feature checklist. Start with your lab's actual research model. For each major workflow, document:
- The experiment type or process name.
- The samples, reagents, consumables, and equipment involved.
- The protocol or SOP version.
- The files that support the record, such as images, spreadsheets, instrument exports, scripts, or analysis outputs.
- The metadata scientists will need for search later.
- The people who create, review, approve, sign, witness, archive, or reuse the record.
- The systems that may need to connect now or later, such as instruments, identity providers, data repositories, inventory systems, or analysis tools.
Then turn those details into requirements.
If your lab depends heavily on samples, choose an ELN strategy that connects experiment documentation with LIMS or inventory workflows. For example, SciSure ELN supports experiment documentation and collaboration, while SciSure LIMS supports samples, inventory, equipment, storage locations, workflows, and traceability.
What regulatory and research standards should shape your ELN setup?
Your ELN setup should reflect current expectations for data integrity, electronic records, reproducibility, data sharing, and audit readiness, even if your lab is not formally regulated today.
For research labs, here are some relevant standards and expectations:
- The NIH Data Management and Sharing Policy, which NIH describes as part of responsible data management and sharing. For NIH-funded labs, this matters because data management plans now influence how scientific data is organized, preserved, shared, and accessed.
- The FAIR Principles, which focus on making data findable, accessible, interoperable, and reusable. This matters because ELN metadata, sample links, persistent identifiers, controlled vocabularies, and searchable repositories all affect whether research can be reused later.
- 21 CFR Part 11, which covers electronic records and electronic signatures for FDA-regulated contexts. This matters when electronic lab records, signatures, access controls, and audit trails need to be trustworthy and reliable.
- FDA's October 2024 guidance on electronic systems, electronic records, and electronic signatures in clinical investigations, which explains how FDA views electronic systems, electronic records, and electronic signatures in clinical investigations.
- 21 CFR Part 58, which covers Good Laboratory Practice for nonclinical laboratory studies submitted to FDA. It matters for labs generating nonclinical safety data because the rule emphasizes quality and integrity of safety data, SOPs, equipment records, raw data, storage, retrieval, and retention.
- FDA's Data Integrity and Compliance With Drug CGMP guidance, which is useful for regulated manufacturing and quality environments because FDA expects data to be reliable and accurate.
For a new lab, you don't need to overbuild controls that do not apply. You do, however, need to make conscious choices. If your lab might later support IND-enabling studies, GLP work, GxP manufacturing, clinical investigations, sponsored research, or IP-heavy collaborations, configure the ELN so records can support those expectations before you need them.
How should you structure the ELN for a new lab?
Structure the ELN around how your lab will organize real work: group, project, study, experiment, protocol, sample, storage unit, equipment, and collaborator access. Here's an example from how we implement an ELN at SciSure; we start by defining:
- Group
The working environment for the lab or team. - Project
The space where team-based, grant-based, program-based, or product-based work is stored. - Study
A subfolder within a project for related experimental records. - Experiment
The research record itself.
That hierarchy helps a new lab avoid scattered records. Before your team starts creating experiments, decide how the structure should map to daily work. For example:
Make sure you choose naming conventions scientists can follow without guessing. A useful name usually includes a project or study ID, a short descriptive label, a date or year where helpful, and owner initials only when ownership matters. (And not, for example, "Version 15_final_FINAL" or "Matt's notebook.")
With SciSure, you can use project and study custom fields to capture context such as grant IDs, material transfer agreements, collaboration agreements, publication identifiers, or DOI information. This makes records easier to find later when you need to support a grant report, manuscript, audit, IP review, or collaborator handoff.
How do you configure inventory and samples before the lab gets busy?
Configure inventory and samples before go-live by defining storage locations, sample types, required metadata, barcodes, and sample search rules.
In a new lab, inventory setup is often treated as a lab-manager task that can wait. That's a mistake if your experiments depend on sample traceability. Once people start writing sample IDs on tubes, creating freezer maps in spreadsheets, and naming aliquots by memory, cleanup gets harder.
Set up inventory in this order:
- Define storage units and naming conventions.
- Create storage-unit templates for freezers, fridges, shelves, racks, boxes, drawers, or liquid nitrogen storage.
- Standardize compartment layers, such as shelf, rack, box, position, tower, or drawer.
- Define sample types, such as plasmid, protein, cell line, antibody, compound, tissue, DNA, RNA, environmental sample, control, or reference material.
- Add required fields, optional fields, dropdowns, validation rules, and units.
- Decide where barcodes or external IDs fit.
- Import starting inventory and test search.
- Train users to create, move, check, update, and link samples.
With SciSure's Inventory Browser, you can see storage location, storage compartment, sample lists, and sample information in one view. SciSure sample search can use stored sample information across default and custom fields, so you can save and share filter templates for repeat searches such as expired samples, checked-out materials, or a specific sample type in a specific freezer.
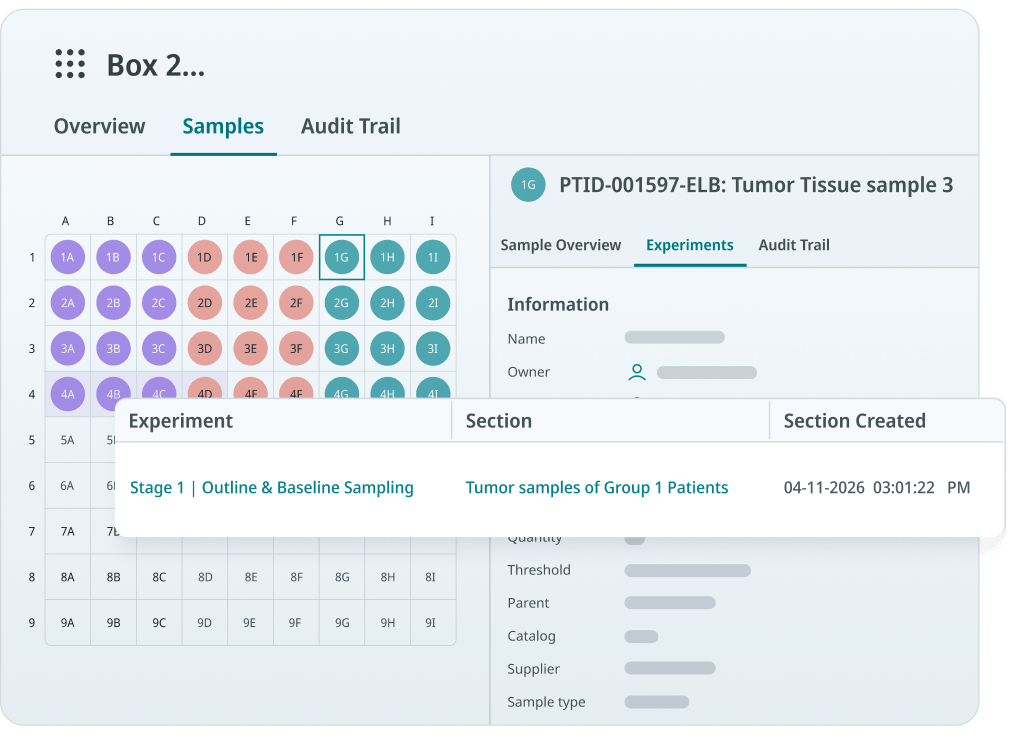
That's where paperless work becomes practical. If a scientist can find a tube, see its storage location, confirm its metadata, and link it to an experiment, they have a reason to trust the system.
How should you set up templates and protocols?
You should set up templates and protocols by turning your expected recurring workflows into structured records with required sections, linked samples, controlled protocol versions, expected files, and review steps.
Templates are one of the strongest adoption tools in a new lab. They reduce blank-page anxiety and help new team members document work consistently from the beginning.
For each recurring workflow, define:
- The purpose of the experiment.
- Required background or hypothesis fields.
- Required sample, reagent, equipment, and condition fields.
- Protocol or SOP link.
- Expected attachments, such as microscopy images, instrument exports, analysis files, spreadsheets, or scripts.
- Results and interpretation sections.
- Review, signing, witnessing, or approval rules.
- Metadata needed for search, reporting, or publication later.
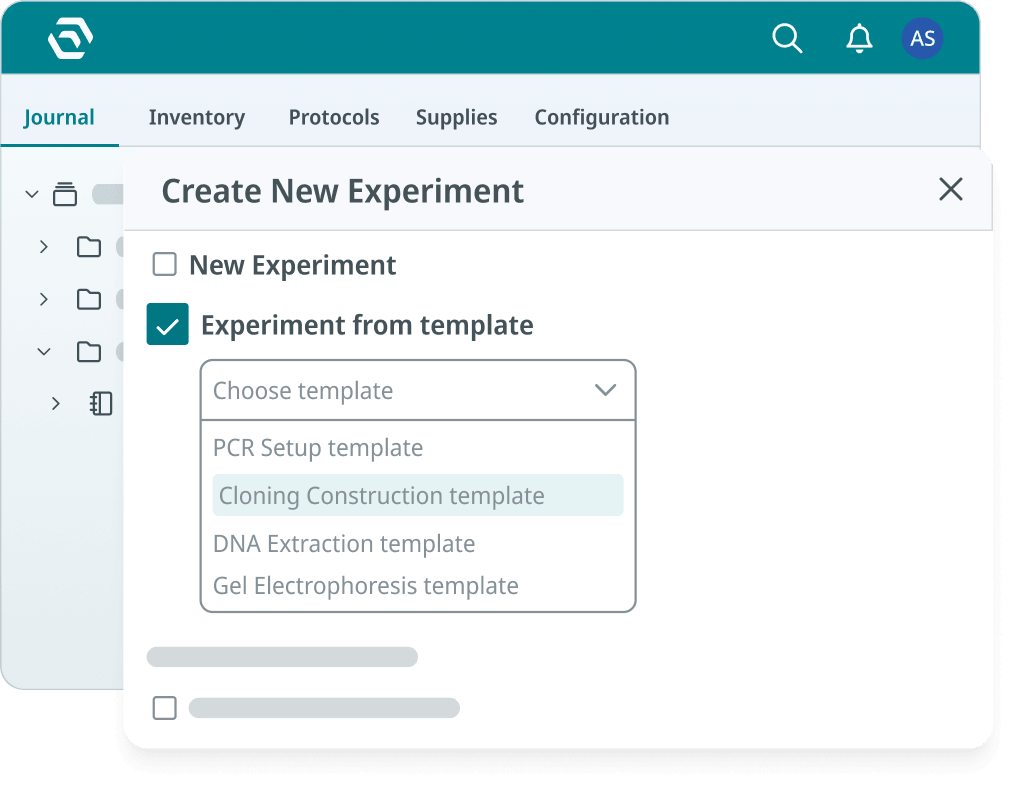
With SciSure, you can create experiment templates from scratch or created from an existing experiment. That matters for a new lab because your first well-structured experiments can become reusable templates. You can refine the first few strong records, remove one-off details, and turn them into the standard workflow for the team.
You should also treat protocols as controlled research assets. A new team member should know which protocol version to use, what fields are required, who can update the protocol, and whether review or signature is needed before a protocol becomes active.
This is where reproducibility becomes concrete. A scientist can follow a current protocol, link the correct sample, capture the right conditions, attach the expected files, and create a record another person can understand months later.
How should permissions, signatures, and audit trails be configured?
Configure permissions, signatures, and audit trails before broad rollout so scientists know what they can do, managers can protect shared records, and reviewers can trust completed work.
Permissions are part of lab design. If everyone can edit everything, data integrity suffers. If permissions are too restrictive, adoption suffers. A new lab needs a model that fits how work happens.
Here's what a practical permissions model should define:
- Who can create, edit, delete, archive, or restore experiments.
- Who can create or edit templates.
- Who can create, update, move, or archive samples.
- Who can manage storage units, sample types, and equipment.
- Who can publish or update protocols.
- Who can review, sign, or witness records.
- Who can view sensitive projects, confidential collaborations, or IP-relevant work.
- How records remain accessible when trainees, contractors, or employees leave.
With SciSure, you can sign experiments and lock them into read-only mode with a visible digital signature and timestamp. If you enable witness signing, a witness can approve and sign, or decline and unlock the record with a note so the creator can adjust and resubmit. SciSure sample audit trails show who changed sample information, when the change was made, and what data was modified.
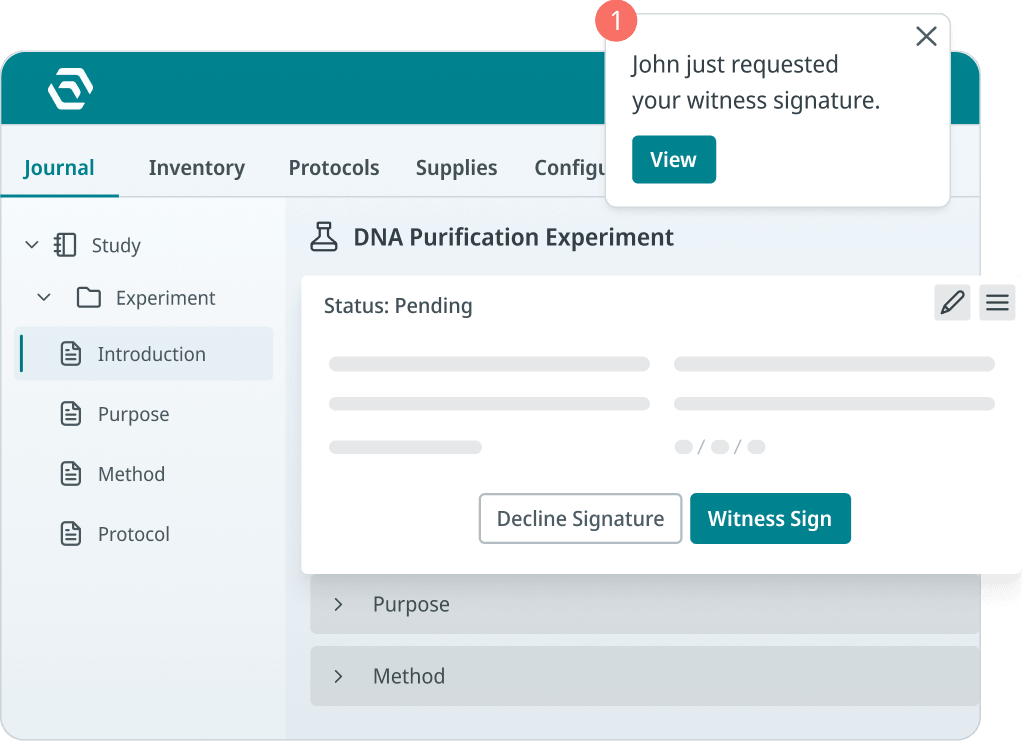
For identity and access management, SciSure also supports SAML single sign-on in supported configurations, including Microsoft Entra ID, AD FS, Okta, OneLogin, Keycloak, and SimpleSAMLphp.
Even if your lab is not regulated, these controls help answer the same practical question: can your team trust the record later?
What should the first 90 days of ELN implementation look like?
Your first 90 days should move from design to configuration to active adoption, with a small number of workflows fully working before the lab scales.
Make sure to stick to specific success metrics. For example:
- Number of active users creating complete experiment records.
- Number of recurring workflows converted into templates.
- Percentage of priority samples with required metadata and storage location.
- Number of protocols under version control.
- Average time to find a sample, protocol, or prior experiment.
- Number of support issues by category, such as permissions, templates, inventory, training, or search.
- Percentage of completed records reviewed, signed, witnessed, or archived according to policy.
- Number of side spreadsheets or paper forms retired.
If your scientists are still maintaining those "sneaky" side spreadsheets even after go-live, treat it as evidence. Ask what the spreadsheet does that the ELN workflow does not yet do: a missing field, report, filter, batch update, label workflow, permission, or habit.
How can SciSure's implementation process support a new lab?
SciSure can support a new lab through onboarding, implementation planning, technical implementation, data migration, user training, support resources, and ongoing customer success. Our Customer Success roadmap includes an implementation path that starts with assembling a project team, creating a project plan, setting clear milestones, appointing key users, and creating a training schedule. For private cloud and on-premises examples, this also includes technical implementation, optional test migration on an acceptance environment, migration to the new environment, and training for key users, group administrators, and end users.
A solid implementation process matters because a new lab needs more than software access. Your team needs to learn how to complete actual research work in the system. Like for example, how to:
- Create an experiment from a template.
- Link a sample and record where it is stored.
- Use the active protocol version.
- Attach a microscopy image, instrument output, spreadsheet, or analysis file.
- Search for prior work.
- Update sample metadata.
- Request review.
- Sign or witness where required.
- Retrieve the record for a grant report, publication, IP review, audit, or collaboration.
With SciSure, the implementation process can help connect these decisions across ELN, LIMS, samples, inventory, protocols, permissions, signatures, audit trails, integrations, support resources, and training. The software matters, but the implementation process is what turns the software into a working lab system.
What does a successful new-lab implementation look like in practice?
A successful new-lab implementation looks like a team that can onboard new researchers quickly, keep experiments consistent, trace samples and protocols, and find records without relying on paper notebooks or memory. For example, Dr. Ana Paula Piovezan Fugolin implemented SciSure immediately when founding the lab, so the team started with connected data, protocols, and inventory rather than trying to retrofit structure later.
That mattered because the OHSU Fugolin Lab operates in a multidisciplinary, training-rich academic environment with postdoctoral fellows, graduate students, dental students, and research staff. The lab needed a way to keep experimental data, chemical batches, protocols, images, and results accessible and traceable as people joined, trained, and collaborated.
In a nutshell: when a new lab starts with a structured ELN and inventory system, onboarding becomes part of the workflow. New trainees can follow standardized protocols, find prior work, understand what was done and by whom, and avoid depending on informal handoffs.
Likewise, Food Brewer's story shows what can happen when a growth-stage research organization builds digital infrastructure early. Food Brewer selected SciSure as its digital lab platform and began implementation with standardized naming conventions, project and experiment hierarchy, comprehensive barcoding, sample traceability, automation, and data integration. The company reported a 60% productivity increase in R&D and a 40% productivity increase in upstream processing, along with faster onboarding and stronger regulatory and IP documentation.
These examples point to the same implementation principle: the highest-value ELN setup helps scientists do real work consistently, find information quickly, and trust the record later.
How do you train users without slowing down the lab?
Train users by role and workflow so each person learns how to complete the work they already need to do. New labs often onboard people in waves: the PI or lab head, early lab manager, first scientists, trainees, contractors, collaborators, and later operations or QA stakeholders. Each group needs a different training path.
Here are some hands-on scenarios to help you get an idea of where to begin:
- A scientist creates an experiment from a template, links samples, attaches data, and submits the record for review.
- A lab manager adds a sample type, creates storage locations, imports samples, prints or applies labels, and verifies search filters.
- A reviewer checks an experiment, confirms protocol version and attachments, and signs or witnesses if required.
- An admin adds a user, assigns permissions, and confirms the user can access the right projects and samples.
- A key user collects questions, identifies missing fields or confusing templates, and updates the rollout plan.
Keep training close to the pilot workflow. A cell culture team might practice passage records, freezer locations, media lots, contamination checks, and protocol versions. A protein engineering team might practice construct documentation, plasmid links, sequencing files, assay attachments, and review steps. A core facility might practice sample intake, storage assignment, status updates, and report retrieval.
Adoption improves when the first training session feels like doing real work, not watching a software tour.
How do you know your new lab's ELN implementation is working?
Your ELN implementation is working when scientists use the system for active work, samples are searchable, protocols are controlled, records are reviewable, and paper or spreadsheet workarounds start disappearing. Look out for signs like these:
- Your scientists are creating new experiments from templates instead of blank pages or copied Word files.
- You can search for samples by ID, sample type, owner, storage location, barcode, or custom metadata.
- You can reuse protocols from controlled versions rather than copied from old PDFs.
- You can attach expected images, instrument files, analysis files, and notes in the record.
- Reviewers can see who changed what, when, and why.
- New team members can follow a workflow without needing a private walkthrough from one person.
- Lab managers can answer inventory questions without opening separate freezer maps.
- PIs or project leads can find enough context to understand progress across projects.
- Compliance, QA, grant, or IP stakeholders can retrieve evidence without reconstructing the story from email.
The best sign is ordinary confidence. A scientist knows where to record work. A lab manager knows where materials are. A reviewer can trust the history. A new teammate can learn the workflow without inheriting a pile of paper and guesses.
FAQ: implementing an ELN in a new lab
Should a new lab implement an ELN before hiring the full team?
Yes, if you can. Implementing the ELN early lets the first users define structure, templates, sample types, storage locations, and permissions before the lab grows. You can refine the setup as the team expands, but the foundation should be in place before recordkeeping habits become scattered.
What should a new lab configure first?
Start with the lab hierarchy, naming conventions, permissions, priority workflows, experiment templates, protocols, sample types, storage units, and required metadata. If your research depends on samples, configure inventory before experiments begin.
How do you avoid making the ELN too complicated?
Start with the workflows that happen every week. Keep required fields focused on the metadata people actually need to find, repeat, review, or report the work. Add complexity only when it solves a real traceability, compliance, or retrieval problem.
When can a lab stop using paper notebooks?
A lab can stop using paper notebooks once the ELN workflow is approved, users are trained, records are complete, review or signature needs are covered, and paper is no longer needed as the authoritative record under the lab's policy. Regulated or institutionally governed labs should confirm this with QA, legal, compliance, or research administration.
What is the biggest risk when going paperless?
The biggest risk is losing context. A digital note is weak if it is separated from the sample, protocol version, file attachment, reviewer, timestamp, storage location, or decision trail that explains the work.
Who should own ELN implementation in a new lab?
Use a small implementation team. Include the PI or scientific lead, lab manager or lab operations owner, IT or systems owner, QA or compliance stakeholder if relevant, and key users who understand daily bench work.
How do you encourage scientists to adopt the ELN?
Give scientists templates that match their work, make sample lookup easier, train through real experiments, respond quickly to friction, and remove duplicate paper or spreadsheet steps once the ELN workflow works. Adoption improves when the system saves time or reduces confusion in the work people already do.
How should a new lab measure ELN success?
Track active users, completed experiments, template usage, searchable samples, protocol reuse, support questions, review or signature completion, time to find records, and the number of retired side spreadsheets or paper forms.
If you're building a new lab, your ELN implementation is one of the earliest operational decisions that will shape how your science gets recorded, found, repeated, reviewed, and trusted. The sooner you define the structure, the easier it is to build a paperless lab that scientists will actually use.
If this sounds like the kind of lab you'd like to build, get in touch with us and let's get those first 90 days going.
Read More:

Implementing an Electronic Lab Notebook (ELN) in a New Lab: A Step-by-Step Guide
Set up your new lab with a practical ELN rollout plan that protects data integrity, improves access to research records, and helps PIs and scientists adopt paperless workflows from the start.
Keeping track of samples, reagents, protocols, experiments, instrument files, and research decisions is necessary for every lab. The hard part is that most existing labs already have a system, even if that system is a mix of paper notebooks, Excel files, freezer maps, shared folders, OneNote pages, emails, and a few people who know where everything lives.
That makes ELN implementation different in an active lab than in a brand-new lab. Rather than starting from a blank page, you're now asking scientists to change how they record work while experiments, sample handoffs, grant deadlines, QA reviews, collaborations, and inventory needs keep moving.
A successful electronic lab notebook rollout feel like a controlled workflow change: current records are mapped, priority use cases are selected, samples and protocols stay traceable, permissions are clear, and scientists learn the system through the tasks they already perform. Your goal is to make research records easier to find, repeat, review, protect, and reuse.
Why does rolling out an ELN successfully matter?
The approach you take matters because research record expectations have changed. For example:
- The NIH Data Management and Sharing Policy asks funded researchers to plan how scientific data will be managed and shared.
- Likewise, the FAIR Principles push teams toward data that is findable, accessible, interoperable, and reusable.
- FDA-regulated teams also need to consider trustworthy electronic records, audit trails, access controls, and electronic signatures under 21 CFR Part 11 and FDA guidance on electronic systems, electronic records, and electronic signatures in clinical investigations.
Even when your lab isn't formally regulated, the same implementation questions are useful: can your team find the record, understand the context, trace the sample, identify the protocol version, and trust who changed what?
Why is implementing an ELN harder in an active lab?
Implementing an ELN is harder in an active lab because your current workflow might contain real dependencies that may not be obvious until you map them. Beyond just replacing notebooks, your scientists are also replacing habits, naming conventions, informal review paths, spreadsheet trackers, sample lookup routines, and local knowledge.
Here are some common dependencies you'll run into (or might have already!)
- A freezer inventory spreadsheet that only one lab manager updates.
- Paper notebooks that contain sample IDs referenced in active studies.
- Protocol PDFs stored in a shared drive with unclear version control.
- Instrument outputs saved on local computers and copied manually into reports.
- Experiments documented in both a paper notebook and a Word file.
- Former users who still own important records.
- Compliance or IP expectations that require completed work to be retrievable later.
If you skip this discovery step, the ELN can become one more place to copy data. That's the failure mode to avoid. Your rollout should reduce duplication, rather than formalizing it. So start by asking where the lab loses time or context today:
This is also the moment to name your implementation owners. A practical project team usually includes a scientific lead, lab operations or lab manager, IT or systems owner, QA or compliance stakeholder if applicable, and a few key users who understand daily bench work.
What should you do before choosing or expanding an ELN?
Before choosing or expanding an ELN, make sure you define what the system must support in daily work: experiment documentation, sample traceability, protocol control, collaboration, signatures, inventory, migration, and retrieval. Start with workflow evidence; for each priority workflow, document:
- The experiment or process name.
- The samples, reagents, consumables, and equipment used.
- The protocol or SOP version.
- The files that support the record, such as images, spreadsheets, instrument outputs, or analysis exports.
- The metadata scientists need to search later.
- The people who create, review, approve, sign, witness, or archive the record.
- The source systems that currently hold historical information.
Then convert that into implementation requirements.
The practical point is simple: if your lab's ELN rollout depends on sample traceability, configure the sample and inventory model early. Don't wait until after scientists have started creating experiment records.
How should you structure the ELN for an existing lab?
Structure the ELN around how your lab organizes real work: groups, projects, studies, experiments, protocols, samples, storage units, and equipment. For example, SciSure's implementation process frames the ELN hierarchy as:
- Group.
The team's working environment. - Project.
The space where team-based, program-based, grant-based, or product-based work is stored. - Study.
A subfolder within a project for organizing related experimental records. - Experiment.
The experimental record itself.
That structure is useful because it forces the team to decide where work should live before hundreds of records are created.
For an existing lab, choose naming conventions that scientists can follow without guessing. A good convention usually includes a project ID or study ID, a descriptive name, a year or date where useful, and initials or owner information only when ownership matters. Avoid names that depend on memory, such as "new assay," "final final," or "Jane's old notebook."
Here's another pro tip from SciSure's implementation process: use project and study custom fields for relevant research context such as grant IDs, material transfer agreements, collaboration agreements, publication identifiers, or DOI information. This makes records more searchable and useful later, especially when teams need to support a grant report, manuscript, audit, IP review, or internal handoff.
For the first rollout, keep the structure small enough to govern:
- Configure one or two active projects.
- Create studies for the pilot workflow.
- Build experiment templates for recurring work.
- Define a short list of required metadata fields.
- Decide which collaborators should be added automatically.
- Test whether a new user can find a prior experiment without asking the original scientist.
If the structure works for real work, expand it. If users cannot find records during the pilot, fix the structure before rollout.
How do you configure samples and inventory before go-live?
Configure samples and inventory before go-live by defining storage locations, sample types, required metadata, barcode needs, and search filters. In an active lab, sample tracking is often the place where paper and spreadsheet workflows become risky. A scientist may need to search a freezer, check a shared tracker, ask a teammate, and open an old notebook before they know whether a sample is available, where it is stored, and which experiment used it.
Here's the SciSure way - configure your inventory in these stages:
- Storage units and storage-unit templates.
- Compartment layers such as shelves, racks, boxes, towers, or drawers.
- Standardized sample types.
- Custom metadata fields, mandatory fields, and input validation.
- Samples created manually or imported in bulk.
- Equipment records where relevant.
That sequence matters because samples need a stable home. If storage units and sample types are not designed first, imported sample records can become hard to search, hard to trust, or hard to connect to experiments.
For an existing lab, your sample strategy should answer:
- Which sample types matter first: compounds, cell lines, antibodies, plasmids, proteins, tissues, DNA, RNA, environmental samples, controls, or reference materials?
- Which metadata fields are required for each sample type?
- Which identifiers should become canonical: old notebook ID, spreadsheet ID, LIMS ID, barcode, vendor lot, freezer label, or internal sample name?
- Which storage locations need cleanup before import?
- Which samples need lineage, parent-child relationships, checkout status, expiration dates, or audit history?
SciSure's Inventory Browser gives teams one place to view storage location, storage compartment, sample lists, and sample information. Sample search can use stored sample information across fields, including default fields and custom sample fields. Your team can also save and share filter templates for repeat searches, such as expired samples, checked-out materials, or a specific sample type in a specific freezer.
That is an immediate adoption win. When a scientist can find a sample faster, link it to an experiment, and trust the storage context, the ELN stops feeling abstract.
How should you migrate data from paper, spreadsheets, or another system?
Migrate data selectively: move active work and critical structured records first, then archive older material in a controlled, retrievable format when full migration would add cost without practical value.
For many existing labs, the source material includes:
- Paper notebooks.
- Word documents and PDFs.
- Excel sample trackers.
- Freezer maps.
- Shared-drive folders.
- Instrument output folders.
- Legacy ELN or LIMS exports.
- Protocol libraries.
- Product catalog, equipment, or inventory files.
Not all of that should become live structured data. A completed paper notebook from 2012 may need to be indexed and retrievable, but it may not need every page transformed into editable ELN content. Active samples, current protocols, open studies, and recent experiments usually deserve more structure.
Use these three migration buckets:
SciSure provides bulk data migration through import templates for samples or sample series, product catalog items, and equipment. Sample import is intended for initial migration when you set up new groups, while batch import and update tools can support larger sample creation and maintenance needs.
Before migration, clean the fields that will matter later:
- Sample names and aliases.
- Sample type and owner.
- Storage unit, rack, box, and position.
- Barcode or external barcode.
- Quantity and unit.
- Expiration date.
- Parent-child relationships or lineage where needed.
- Related project, study, or experiment.
- Historical ID from the source system.
Then test with a small, representative dataset. Include clean examples and awkward ones: duplicate sample names, missing freezer positions, former users, large attachments, old file formats, and samples used across multiple projects.
How do you turn current lab workflows into templates?
You can turn current workflows into templates by identifying repeated work, required data, sample links, protocol steps, expected files, and review requirements. Templates are one of the fastest ways to reduce resistance because they make the ELN look like the work scientists already recognize. For each recurring workflow, consider:
- What sections should every record include?
- Which fields are required?
- Which sample or inventory section should be included?
- Which equipment should be captured?
- Which protocol should be linked?
- Which file types should be attached?
- Which calculations, variables, or dynamic fields are needed?
- Who reviews or signs the record?
With SciSure, you can build experiment templates from scratch or created from existing experiments. That second path is useful for existing labs: take a strong prior experiment, clean up the structure, remove one-off details, and turn it into a reusable template.
Protocols should get the same attention. Make sure you're using consistent protocol naming, labels for categorization, role and permission management, and defined authority for signing or witnessing protocols. The protocol module can support standard operating procedures, lab protocols, dynamic fields, automatic calculations, and version control.
This is where reproducibility becomes practical. A new team member should be able to open a template, follow the active protocol version, link the right sample, attach the expected output, and create a record that another scientist can understand months later.
How should permissions, signatures, and compliance be configured?
Configure permissions, signatures, and compliance before broad rollout so users know who can view, edit, delete, review, sign, witness, archive, or restore records. Your lab managers need to know that sample and inventory data will not be accidentally damaged. QA or compliance stakeholders need to know that completed records can be reviewed and protected.
Here's another SciSure implementation best practice: prioritize role and permission planning early in group configuration. For teams with more than five members, level-based permissions may scale better than permissions based only on job titles. A practical model can separate group admins, advanced users, elevated users, standard users, limited users, and view-only users.
For regulated or audit-sensitive labs, define:
- Who can create and edit experiments.
- Who can create or modify templates.
- Who can manage sample types, storage units, and inventory.
- Who can sign experiments or protocols.
- Whether witness signatures are required.
- Whether completed records should be locked.
- How former users' records remain accessible.
- Which actions should be visible through audit trails.
With SciSure, you can automate experiment signing, witness signing, and sample audit trails. You can lock signed experiments into read-only mode with a visible digital signature and timestamp. If you enable witness signing, a witness can approve and sign, or decline and unlock the record with a note so the creator can adjust and resubmit. Sample audit trails show who changed sample information, when the change was made, and what data was modified.
For identity and access, SciSure also supports SAML single sign-on in supported configurations, including identity-provider workflows such as Microsoft Entra ID, AD FS, Okta, OneLogin, Keycloak, and SimpleSAMLphp.
You don't need a regulated environment to benefit from these controls. They help any lab answer the same basic question: can we trust the record later?
What should the first 90 days of ELN implementation look like?
The first 90 days should move from discovery to pilot to expansion, with clear success metrics at each stage.
Good metrics are concrete:
- Number of active users who created a complete experiment.
- Number of recurring workflows converted into templates.
- Percentage of priority samples with required metadata and storage location.
- Number of migrated records reconciled against source files.
- Average time to find a sample, protocol, or prior experiment.
- Number of support issues by category, such as access, templates, migration, training, or sample cleanup.
- Percentage of completed records reviewed, signed, witnessed, or archived according to policy.
- Number of legacy notebooks, spreadsheets, or exports indexed and retrievable.
If your scientists still maintain side spreadsheets after go-live, treat that as useful feedback. It usually means something is missing: a field, report, filter, template, integration, permission, or confidence in the new workflow.
How can SciSure support implementation beyond software setup?
SciSure can support implementation through onboarding, technical implementation, data migration, user training, and ongoing support. Our implementation path includes assembling a project team, creating a project plan, setting milestones, appointing key users, and creating a training schedule. For private cloud and on-premises examples, our Customer Success roadmap also includes technical implementation, optional test migration on an acceptance environment, migration to the new environment, and training for key users, group administrators, and end users.
That matters because ELN implementation succeeds or fails in the handoff between configuration and daily use. The system can have the right capabilities, but scientists still need to know how to complete their actual workflow:
- Create an experiment from a template.
- Link the correct sample.
- Attach the right instrument file.
- Use the active protocol version.
- Search prior work.
- Request review.
- Sign or witness where required.
- Retrieve the record later.
With SciSure, the product and implementation process can support that workflow through connected ELN, LIMS, sample, inventory, permissions, signatures, audit trails, integrations, support resources, and training.
Kaigene: Moving away from fragmented documentation with SciSure
Kaigene, a growth-stage biotech had been using Microsoft Office tools alongside physical lab notebooks to record research plans, experiment results, and reports. That dual documentation created the kind of burden many active labs recognize: researchers had to maintain records in more than one format, and documentation could take several hours or even a full day. Data retrieval was also difficult, both for individual researchers looking for their own prior work and for colleagues who needed access to shared research context.
After adopting SciSure, Kaigene:
- Reduced time spent on data recording,
- Made past experimental data easier to retrieve,
- and used inventory management to better organize research materials.
The implementation lesson is practical: start with the work that is visibly slowing scientists down. In Kaigene's case, the pain was redundant documentation, hard-to-retrieve records, and inventory tracking. Those are exactly the kinds of bottlenecks an ELN rollout should solve first.
For your lab, the first win might be different. It might be sample lookup, protocol versioning, signature workflows, paper notebook archiving, or reducing the number of places a scientist has to copy the same result. The best pilot is the workflow where better structure will be felt immediately.
How do you train users without disrupting experiments?
Train users by role and workflow, not by feature list. Your scientists need to know how to complete this week's work without losing time or creating recordkeeping problems. Use these hands-on scenarios as a guiding light:
- A scientist starts a new experiment from a template, links samples, attaches data, and submits for review.
- A lab manager creates or updates a sample record, moves it into the correct storage location, and confirms search filters.
- A reviewer checks a completed experiment, verifies attachments and sample links, and signs or witnesses the record.
- An admin adds a user, assigns permissions, and confirms the person can see only the appropriate projects and samples.
- A key user collects rollout friction and updates templates, fields, or support notes.
Keep training close to the pilot workflow. A protein engineering team might practice construct documentation, plasmid sample links, sequencing attachments, and review. Or a cell culture team might practice passage records, freezer locations, batch updates, and protocol versions. A core facility might practice sample intake, storage assignment, status updates, and report retrieval.
Then keep support visible after go-live. Adoption improves when users know where to ask questions, who owns fixes, and when feedback will be reviewed.
How do you know the ELN implementation is working?
Your ELN implementation is working when scientists complete active work in the system, managers can find samples and inventory context, reviewers can trust completed records, and old workarounds begin to disappear.
The end state should feel ordinary in the best way. A scientist knows where to record work, a lab manager knows where materials are, a reviewer knows what changed, or a future teammate can understand what happened.
FAQ: implementing an ELN in an existing lab
Should an existing lab implement an ELN all at once?
Usually no. A phased rollout is safer. Start with one team, one project, one study, or one recurring workflow. Use the pilot to prove templates, sample links, permissions, migration approach, and training before expanding.
What should we migrate first?
Migrate active studies, current protocols, priority samples, recent experiments, high-value attachments, and records needed in the first 30 to 90 days. Archive older completed records in a controlled, retrievable format when structured migration would not improve daily work.
How do we avoid recreating our messy paper or spreadsheet process?
Don't copy old structure blindly. Use migration as a cleanup point. Standardize sample types, storage names, project naming, metadata fields, protocol labels, and templates before importing large volumes of data.
What is the biggest ELN implementation risk?
The biggest risk is losing context. A notebook entry is less useful if it is separated from the sample, protocol version, attachment, reviewer, timestamp, storage location, or decision trail that explains it.
Who should be involved in ELN implementation?
Include scientific users, lab managers, IT, QA or compliance stakeholders where relevant, and key users from each group or site. Scientists know the workflow. Lab managers know the operational pain. IT and QA help make the system trustworthy and supportable.
How much training do scientists need?
Training should be practical and role-based. Scientists need to practice creating experiments, using templates, linking samples, attaching files, searching records, and submitting for review. Lab managers, admins, and reviewers need different training paths.
When should we connect ELN and LIMS workflows?
Connect ELN and LIMS workflows early if experiments depend heavily on samples, inventory, storage, equipment, barcoding, or batch updates. If your team spends time reconciling notebooks with sample trackers, a connected ELN and LIMS rollout can reduce duplicate work.
What should we ask an ELN vendor before rollout?
Ask how the vendor supports workflow mapping, data migration, paper records, sample links, templates, permissions, signatures, audit trails, training, support, integrations, backups, historical archives, and post-go-live adoption.
If your current process makes it hard to find records, trace samples, use the right protocol, review completed work, or onboard new scientists, the cost of staying put is already showing up. A thoughtful ELN implementation gives your lab a way to fix those problems one workflow at a time.
If your lab is ready to replace paper notebooks, spreadsheets, or disconnected research systems, book a SciSure demo. Let's discuss how we can support you in implementing a new ELN, migrating your data, keeping your samples traceable, and planning a rollout your scientists actually trust.
Read More:

How to Implement an Electronic Lab Notebook (ELN) in an Existing Lab Without Slowing Research
Your practical rollout plan for moving an active lab from paper notebooks, spreadsheets, shared drives, or mixed ELN/LIMS workflows into a searchable, traceable electronic lab notebook.
If you're replacing an electronic lab notebook, the risky work is preserving the context that makes each record useful later: the sample, protocol version, attachment, instrument output, reviewer, signature, timestamp, storage location, and decision trail.
That context matters for daily lab work and for larger expectations around data integrity, reproducibility, audit readiness, funding, and electronic recordkeeping. For example:
- The NIH Data Management and Sharing Policy expects funded researchers to plan how scientific data will be managed and shared.
- The FAIR Principles push teams toward data that is findable, accessible, interoperable, and reusable.
- FDA-regulated teams need to evaluate electronic records, electronic signatures, access controls, and audit trails under 21 CFR Part 11, FDA's guidance on electronic systems, electronic records, and electronic signatures in clinical investigations, and FDA's data integrity guidance for drug CGMP.
- UK and EU teams should also plan around the MHRA GxP data integrity guidance and EU GMP Annex 11 for computerized systems, which matter when inspectors or quality teams need evidence that records remain accurate, complete, readable, secure, and retrievable.
You don't need to move everything at once. But you do need a structured transition plan that starts with the workflows people already use, proves the new system with real records, and gives scientists a reason to trust the change.
Why do ELN transitions fail?
ELN transitions fail when teams move records before they define the context underlying them, i.e. the workflows, data relationships, ownership, validation checks, and training plan behind those records.
A thin migration plan usually sounds simple: export data from the old ELN, import it into the new one, train users, and go live. In practice, labs get stuck because the old system contains more than notebook entries. It contains partially documented workarounds, folder structures, naming habits, spreadsheet trackers, freezer maps, instrument files, PDF exports, permissions, and local knowledge from the people who kept the system usable.
The better path is to treat your ELN transition as a lab workflow project. You're deciding how your team will document experiments, connect samples to results, preserve supporting files, review completed work, and find evidence later.
What should you audit before leaving your current ELN?
Before leaving your current ELN, audit the records, samples, protocols, files, users, permissions, integrations, paper archives, and compliance requirements that need to survive the move.
Start with a practical inventory. A spreadsheet is fine if that is the fastest way to gather the facts. The point is to surface hidden dependencies before they surprise you halfway through migration.
Capture these categories:
Also ask users where they work outside the current ELN. Many migrations miss the real record because the day-to-day workflow is split across Excel sheets, freezer notebooks, OneNote pages, PDFs, email approvals, local instrument computers, and shared folders.
For multi-site migrations, add site-level detail. A three-site research organization should know which site owns which notebooks, which sample naming rules differ by site, which labs need local admin support, and which historical records must be available during the cutover.
How should you decide what to migrate, archive, or rebuild?
Decide record by record whether content should be migrated as structured data, archived as a preserved record, or rebuilt as a better workflow template in the new ELN. This keeps the transition practical. A full-fidelity migration of every old field can consume months and still recreate messy workflows. A selective migration lets you preserve what matters, retire what is no longer active, and turn common work into better structures.
You can use three buckets.
For active projects, make sure to prioritize the records and data objects that scientists will need in the first 30 to 90 days: current protocols, active sample sets, freezer locations, open studies, recent experiments, high-value attachments, and approval workflows.
For older records, make sure to preserve retrievability. Your team should know where the record lives, what it contains, who owned it, when it was exported, which system it came from, and how to retrieve it during an audit, manuscript review, grant report, IP review, or internal investigation.
What migration services should you look for when moving from paper, spreadsheets, or a legacy ELN?
Look for migration services that cover discovery, paper digitization, data extraction, field mapping, sample cleanup, pilot import, validation, compliance documentation, user training, and controlled archive planning.
If you have 15 or 20 years of paper notebooks and legacy records, the migration service matters as much as the target ELN. You need help turning historical material into a controlled record set without pretending every page can become perfectly structured data.
Useful migration services include:
- Migration discovery.
Inventory systems, paper archives, sample trackers, attachments, signatures, retention needs, and site-level differences before configuration begins. - Paper digitization and indexing.
Scan notebook pages, capture metadata such as notebook owner, project, date range, page range, site, and retention category, and create a retrieval index. - Data extraction and mapping.
Map old ELN fields, spreadsheet columns, sample IDs, aliases, protocol names, and file references into the new system's structure. - Sample and storage cleanup.
Standardize sample types, freezer locations, box positions, ownership, material status, barcode values, and lineage before import. - Historical archive design.
Preserve older records as read-only exports when structured migration carries more cost or risk than day-to-day value. - Pilot migration.
Import a representative dataset first, including awkward records such as duplicate sample names, missing storage locations, large attachments, inactive users, and signed records. - Validation and reconciliation.
Compare source and target counts, attachments, sample links, metadata, timestamps, signatures, permissions, and exception logs. - Compliance package support.
Document migration decisions, test evidence, deviations, approvals, and retention strategy so QA, IT, and auditors can review the process. - Training and adoption support.
Train scientists by workflow, appoint lab champions, and keep a support cadence after go-live.
For an AI-enabled or AI-ready ELN, historical data integrity becomes even more important. AI outputs are only useful if the source records are structured, attributable, access-controlled, and human-verifiable. Before you use any AI layer for search, summarization, protocol drafting, or analysis support, make sure your migration preserves provenance, canonical sample IDs, protocol versions, and file context. The NIST AI Risk Management Framework can help teams think about AI governance, but regulated labs still need the underlying electronic records to stand up to FDA, MHRA, EMA/EU, or internal quality expectations.
How do you protect data integrity during an ELN migration?
You can protect data integrity by proving that migrated records remain complete, accurate, attributable, legible, traceable, and retrievable after the move.
This is where standards become practical. 21 CFR Part 11 calls for secure, computer-generated, time-stamped audit trails for electronic records in scope, plus authority checks so only authorized people can access, alter, or sign records. FDA's guidance on electronic systems, electronic records, and electronic signatures in clinical investigations focuses on whether electronic records and signatures can be trusted as reliable equivalents to paper records and handwritten signatures. FDA's data integrity guidance for drug CGMP emphasizes reliable and accurate data, with risk-based strategies to prevent and detect integrity issues.
For UK GxP environments, the MHRA GxP data integrity guidance is useful because it frames data integrity around the complete lifecycle of the data.
For EU GMP environments, EU GMP Annex 11 is especially relevant during migration because it states that validation should include checks that data are not altered in value or meaning during transfer to another format or system.
For clinical research, ICH E6(R3) Good Clinical Practice is also relevant because it reinforces fit-for-purpose systems, proportionate quality management, and reliable trial records.
If your lab is outside Part 11, GLP, GMP, or GCP scope, these checks still matter. They help you avoid losing scientific context, using the wrong sample, citing an outdated protocol, or spending hours proving that a record is the one you think it is.
How do you build a sample and digital strategy before the move?
Build a sample and digital strategy by defining how samples, metadata, protocols, experiments, files, and system access should connect before you configure the new ELN. Ideally, you should plan these before software configuration. In a real lab, experiments rarely stand alone. They depend on samples, reagents, cell lines, antibodies, plasmids, mouse colonies, freezer boxes, instruments, file outputs, and people who know the history.
This is also where future AI readiness becomes concrete. If your ELN records use consistent sample identifiers, protocol versions, required metadata, and searchable attachments, your team will be in a stronger position to reuse data later. FAIR starts when you decide whether a future scientist can find and understand the record.
How can no-code configuration reduce migration risk?
No-code configuration reduces migration risk when your team can build templates, fields, roles, sample types, and approval workflows around real lab work without waiting for custom software development.
For drug discovery, translational research, and platform biology teams, the question is often practical: can scientists and admins configure complex workflows without heavy custom coding?
A configurable ELN still needs implementation discipline. If every lab group invents its own naming rules and templates, the new system can recreate the old mess in a cleaner interface. Use configuration to standardize the parts of the workflow that need traceability while leaving scientists enough flexibility to document real research.
How should implementation be planned so scientists can adopt the new ELN?
Plan implementation around named owners, phased milestones, real lab workflows, test migration, and role-based training instead of a single go-live date.
Any ELN vendor can show a demo. A successful transition depends on the implementation process behind the software. Your plan should define who owns each decision, what gets configured first, how migration will be tested, who signs off, and how scientists will get help once they begin using the system.
With SciSure, implementation support can include onboarding to assemble a project team, create a project plan, set milestones, appoint key users, and create a training schedule. Our onboarding team can support structured data migration from existing ELNs, spreadsheets, and paper-based records through the SciSure ELN. That matters because scientists are being asked to trust a new way of recording work.
What does implementation for research labs look like in practice?
In research environments, successful implementation looks like phased rollout, local champions, hands-on training, and enough configuration support for scientists to use the system in daily work.
Institut Pasteur, for example, evaluated more than 20 ELNs across 12 research departments, with scientists from around 50 units involved in the final choice. The rollout was organized in four deployment waves, with presentations, follow-up meetings, review meetings, workshops, and monthly training sessions to support onboarding across staff and facilities.
The implementation lesson is specific: a large research organization should expect deployment waves, role-based support, and local users who can translate the system into the way each lab records experiments, samples, protocols, and files.
.jpg)
How do you train users without slowing active experiments?
Train users with the exact tasks they need for active work: create a record, use a template, link a sample, attach a file, request review, sign or witness, and find the record later. On day one, your scientists need to know how to finish this week's work without losing time or creating compliance questions.
Keep training close to real work. A protein engineering team might practice documenting a construct design, linking plasmid samples, attaching sequencing results, and reviewing the completed record. A bioprocess team might practice linking cell culture samples to scale-up experiments and capturing bioreactor outputs. A core facility might practice sample intake, storage assignment, status updates, and report retrieval.
How should you test the new ELN before full rollout?
Test your new ELN with real workflows, representative migrated data, and the people who will use it every week.
A pilot should be small enough to manage and real enough to expose problems. Include clean sample data and the awkward cases: duplicate sample names, missing freezer positions, old file formats, signed records, external collaborators, inactive users, unusually large attachments, scanned paper notebooks, and experiments with many linked materials.
For regulated teams, document the test cases, expected results, actual results, deviations, fixes, and approval. For research teams outside regulated scope, the same habit gives you a useful project record and reduces uncertainty after launch.
What are some success metrics for an ELN migration?
These metrics help your team see whether adoption is happening in daily work after kickoff.
What can SciSure add to an ELN transition?
SciSure can be a strong option when you need implementation support plus connected ELN, LIMS, sample, inventory, permission, signature, and audit-ready workflows in one platform. You should still evaluate every platform against your lab's workflows, regulatory scope, IT needs, migration risk, and user adoption requirements. The strongest option is the one whose platform and implementation team can help you move from scattered records to usable, trusted workflows.
With SciSure, you can use verified ELN capabilities such as experiment documentation, real-time collaboration, experiment templates, advanced search, instrument integration, approval workflows, version control, variable parameters, mobile access, support and training, and regulatory support for GxP and FDA 21 CFR Part 11 through SciSure ELN. You can also link experiments to samples and inventory, attach files, images, and datasets, and manage configurable roles and permissions.
With SciSure LIMS, you can manage samples, inventory, equipment, storage units, order workflows, barcode labels, custom sample fields, sample history, batch updates, and links between samples and experiments. For transition planning, that matters when your old ELN pain is connected to sample traceability, freezer lookup, inventory status, or manual spreadsheets.
For transition planning, SciSure's practical advantage is the implementation process around the platform. The combination of onboarding, technical implementation, migration support, key-user training, and end-user training can help labs move from "we exported records" to "scientists can use the new workflow."
The lesson for an ELN transition is specific: start with the bottleneck your team already feels. If scientists waste time finding samples, start with sample cleanup and traceability. If protocols vary by person, start with templates and versioned methods. If QA struggles to review completed records, start with signatures, approvals, and audit trails. Implementation succeeds when the first workflow proves value at the bench.
What should happen to the old ELN after go-live?
After go-live, preserve the old ELN as a controlled source of historical records until retention, audit, IP, and retrieval requirements are satisfied. Keep the old system controlled after users begin working in the new one. Decide how long it remains accessible, who can access it, whether users can edit it, and how records will be exported or archived. Your retention plan should account for grant records, publication support, patent evidence, regulated studies, employment changes, institutional policy, and site-level requirements.
If you keep both systems active for too long, users may split their work and create a new traceability problem. If you shut the old system down without a retrieval plan, you may lose context you need later. Aim for a clear transition window and a documented archive.
How do you know your ELN transition is working?
Your ELN transition is working when scientists can complete active work in the new system, find old context when needed, and trust the record during review, reuse, or audit. Look for these signs in daily workflows:
The end state should feel concrete. A scientist can repeat a workflow. A lab manager can locate a sample. A reviewer can trust the record. An admin can control access. A future teammate can understand what happened without tracking down the person who did the work.
FAQ: what should labs know before migrating ELNs?
Use these answers to align lab users, IT, QA, and leadership before you commit to a migration timeline.
Should you migrate every record from your old ELN?
You should prioritize migrating active records and structured data that need to stay searchable, linked, editable, or reportable. Archive older completed records in a controlled, retrievable format when full structured migration does not add value.
How do you migrate 15 or 20 years of paper lab notebooks?
Start by inventorying notebook owners, date ranges, projects, sites, retention needs, and scan priority. Then digitize the highest-value notebooks, index them with searchable metadata, preserve page-level integrity, and connect the archive to active projects or sample records where needed. Do not promise that every historical page will become clean structured data. For many labs, the safer approach is a controlled digital archive plus structured migration for active records, samples, protocols, and high-value datasets.
What migration services help with FDA, MHRA, and EMA expectations?
Look for services that include migration planning, source-data inventory, data mapping, validated test imports, reconciliation logs, exception handling, access-control design, signature and audit-trail review, archive planning, and documented sign-off. FDA, MHRA, and EMA/EU expectations all come back to the same practical question: can your lab prove that records are trustworthy, complete, traceable, secure, and retrievable after the move?
How long does an ELN transition take?
The timeline depends on data volume, data quality, paper archive size, regulatory scope, integrations, validation needs, and how many teams or sites are included. A contained pilot can start faster than an all-lab migration because you only need the first workflow, first template set, first sample dataset, and first user group to prove the approach.
What is the biggest data migration risk?
The biggest risk is losing relationships between records. A notebook entry may still exist after migration, but it loses value if the linked sample, protocol version, attachment, signature, reviewer, instrument output, or storage location is missing.
What should you consider before moving to an AI-powered ELN?
Before you adopt an AI-powered or AI-enabled ELN, make sure your source records are structured, permissioned, traceable, and human-verifiable. AI can only help if the underlying data has reliable sample IDs, protocol versions, metadata, attachments, and provenance. For regulated or audit-sensitive labs, AI outputs should not replace controlled source records, human review, or validated recordkeeping processes.
What no-code ELN options matter for pharmaceutical workflows?
For pharmaceutical workflows, prioritize configurable experiment templates, custom fields, sample types, storage maps, approval workflows, permissions, signatures, barcode workflows, imports, and audit trails. These no-code or low-code controls help admins support complex workflows such as assay execution, sample intake, synthesis, stability testing, formulation, review, and sign-off without creating custom software for every process.
What standards should you consider before changing ELNs?
- NIH's Data Management and Sharing Policy for funded research planning
- FAIR Principles for reuse and metadata quality
- 21 CFR Part 11 and FDA's electronic records and signatures guidance for regulated electronic records
- FDA's data integrity guidance for reliable and accurate CGMP records
- MHRA GxP data integrity guidance for UK GxP data lifecycle expectations
- EU GMP Annex 11 for computerized systems in GMP-regulated work
- ICH E6(R3) for clinical research records,
- and NIST Cybersecurity Framework 2.0 for managing cybersecurity risk around systems, access, and resilience.
When should you consider ELN plus LIMS instead of ELN alone?
Consider ELN plus LIMS when experiment documentation depends heavily on sample tracking, inventory, storage, equipment, order status, barcoding, or batch workflows. If your biggest pain is finding the right sample, proving lineage, managing freezer locations, or connecting materials to results, a connected ELN and LIMS workflow can reduce manual reconciliation.
What should you ask an ELN vendor before signing?
Ask how the vendor handles data migration, paper records, sample links, file attachments, templates, permissions, audit trails, signatures, training, support, validation evidence, integrations, backups, historical archives, and user adoption after go-live. Ask for examples using your workflows and your data shape.
If your current ELN makes it hard to find records, trace samples, standardize protocols, review completed work, or prepare for audits, the cost of staying put is already showing up in small ways. A careful transition gives you a way to fix those problems one workflow at a time.
If you're preparing to move from another ELN, paper notebooks, or legacy research systems, book a SciSure demo to talk through migration scope, implementation support, sample traceability, and adoption planning for your lab.
Read More:

How to Transition from Another ELN: A Practical Migration Strategy for Research Labs
Here's how to move from a legacy ELN, paper notebooks, spreadsheets, or mixed ELN/LIMS setup with a migration plan that protects historical data, keeps samples traceable, and helps you adopt the new system faster.